摘要:随着数据挖掘和分析技术的不断提高,基于大数据方法对经济的研究日益增多,大数据对经济研究和应用具有重要的现实意义。本文梳理了近年来国内外基于大数据方法研究经济的文献,根据经济研究中使用大数据的目的将其大致归纳为3 类:优化传统经济指标或构建其先行指标、构建新的经济预测指标、寻找建立经济变量间的联系。本文介绍了基于大数据方法处理海量非结构化数据并从中获取有效信息的一般方法和主要阶段特征:数据抓取和数据分析,介绍了目前经济学在大数据挖掘和分析方面的主流工具和算法,从经济预测和验证经济理论两方面阐述了目前基于大数据的经济研究的方向,提出了现阶段大数据研究面临的数据获取和数据处理困难、基于大数据的经济分析方法的某些理论基础尚不完善的问题,并在此基础上对我国基于大数据的经济研究进行了展望。本文清晰、全面地展示了目前基于大数据的经济研究的前沿进展和发展,为基于大数据研究经济夯实了基础工作,补缺了近年来国内在基于大数据方法的经济研究综述这一领域的空白。
关键词:大数据; 经济研究; 综述; 前沿进展
基金项目:中国社会科学院登峰战略(产业经济学)优势学科项目“基于大数据的经济监测及预警研究”
李华杰,中国社会科学院工业经济研究所高级工程师、经济学博士生;
马丽梅,中国社会科学院工业经济研究所讲师。
引言
随着互联网、计算机、智能设备的高速发展,人类活动产生的记录数据呈爆炸性增长,数据成为一种重要资源,如何从不断增长的海量数据中挖掘、分析出传统数据和手段无法得到的信息成为国内外政府、企业、学术界近年来关注的热点。自1997年Cox和Ellsworth(1997)、Weiss和Indurkhya(1997)分别从存储和计算方面提出大数据概念以来,随着认识的不断加深,人们对大数据的理解一直在发展:Laney(2001)提出了“3V”,即大量(Volume)、高速(Velocity)、多样(Variety),后来拓展到“4V”,增加了价值(Value),Bello-Orgaz(2016)又提出“5V”,增加了真实(Veracity)。
由于大数据和网络、传输、存储、计算的天然联系,起初大数据的发展和应用主要集中在计算机等自然科学领域,经济学实证研究仍然基于以传统统计理论为基础的计量经济方法和结构化统计数据。但随着技术的不断进步和成熟,大数据拥有的样本海量、实时、数据非结构化等传统统计调查数据无法比拟的特征的实现逐渐成为可能,经济学领域基于大数据方法开展的研究活跃起来,经济学家们在通过大数据分析建立新的或完善已有经济指标、利用实时数据建立现时预测模型、预警经济、分析政策影响、使用大数据验证经济理论等方面做了许多工作,如Akkitas等(2009)[1] 用google搜索数据预测失业率,Bollen等(2011)[2] 通过测量Twitter上文本内容蕴含的情感指标预测经济,Cavallo等(2013)[3] 通过收集大型零售商网站的每日价格更新数据实时计算了阿根廷的通货膨胀率,Bok等(2017)[4] 使用实时数据和动态因子模型建立了纽约联储银行现时预测模型以预测GDP增速。
基于大数据方法的经济研究与传统计量经济研究方法相比有许多新的特征,由于大数据具有的“5V”特征,数据的采集、清洗、分析、使用等均有别于传统的方法。一是基于大数据方法的数据来源和渠道增多,涵盖了信息搜索数据、网络交易数据、网上信息发布、社交媒体数据、智能设备使用产生的数据如位置信息、交通流量监控、卫星灯光数据等,有主动产生的数据,也有被动留下的痕迹,一定程度上对经济学家依靠政府、组织、企业等机构发布数据、设计调查问卷获取数据的传统方法做了有力补充,极大拓展和方便了经济学家的数据来源;二是为处理海量的半结构化、非结构化数据,从茫茫数据中发现经济关系,基于大数据方法的经济学研究中使用了与传统计量统计回归不同的方法,人工智能、机器学习算法如决策树、支持向量机、神经网络、深度学习等算法被引入经济学中处理数据,经济学与计算机、网络、信息技术的联系空前紧密;三是从方法论的角度,基于大数据方法研究经济面临的样本数量和传统方法相比不在一个数量级上,某种程度上大数据方法是在总体范围上建立模型,而传统模型建立在抽样数据基础上,基于大数据方法将有别于传统方法的参数估计和假设检验。
可以预见,任何基于数据分析的学科与大数据的联系将越来越紧密,经济学研究也不会例外。在目前阶段,虽然大数据概念已经提出二十多年,但经济学中真正意义上使用大数据不过是近10来年的事情,基于大数据方法研究经济在某种程度上仍然是较新的、非主流的领域,国内目前关于基于大数据研究经济的文献综述很少,本文系统地梳理了国内外主流文献中近年来基于大数据方法研究经济的文献,以形成脉络清晰的文献综述,并根据主要文献中采用的经济研究中大数据的获取、处理流程,归纳总结出目前基于大数据研究经济的一般方法和研究方向,提出了目前基于大数据研究经济面临的困难,并对大数据在经济学中的应用做了展望。
一、文献回顾
数据是实证经济学的基础、是形成经济指标的背后因素,在宏观经济研究、政策制定、经济理论验证、企业应对市场发展、个人做出经济决策等各领域均有重要作用。如何利用大数据来源渠道丰富、样本海量、更新实时等优势,从用传统统计数据、计量经济方法难以甚至无法处理的数据中获取有用信息和价值,是经济学家们基于大数据方法研究经济的出发点。围绕基于大数据方法研究经济的中文文献目前仍较匮乏,外文文献较多,使用的数据来源极其广泛,包括网络搜索和电子商务、社交媒体、网站、论坛、银行等金融交易、政府纳税记录、城市监控等政府管理数据、GPS定位、卫星灯光图片、智能设备的使用痕迹数据等,数据经过信息提取和特征挖掘后建立经济模型,经过验证后可实时监测、预测、提供政策建议等。Schonberger等(2013)[5] 认为大数据应用的核心是寻找变量间的相关关系做出预测,而不是因果关系。目前,有些关于大数据研究经济的文献按照大数据的来源划分为不同类别:搜索数据、社交媒体、网站信息、电子交易数据、政府管理数据等,有些文献按照大数据的内容和结构划分不同类别:网络内容、用户行为、网络结构等。虽然大数据来源、内容、处理方法不一样,但根据经济研究中使用大数据具有的传统数据不具备的特征和研究的目的可以大致归纳为3类:优化传统经济指标或构建其先行指标、构建新的经济预测指标、建立经济变量间的联系,本文按此类别划分回顾了基于大数据方法研究经济的文献。
在优化传统经济指标或者构建其先行指标方面,大数据有其天然的优势。现有的经济指标如GDP增长率、通货膨胀率、失业率等均由各国政府统计部门通过大量的统计调查、计算后得出,投入大、过程复杂、周期长,且发布往往存在滞后期,很多情况下真实性也难以保障,对政府实时监测经济运行、政策及时制定、企业及时决策、经济研究等均有影响。既然经济指标来自数据,拥有大数据的处理能力后,如何从数据中寻找到关系,利用大数据优化原有经济指标、或构建出有经济意义的新指标是众多经济学家研究的重要课题。Cavallo等(2016)[6] 从2008年开始在麻省理工学院启动“十亿价格计划”,通过抓取900多个零售商的网站上1500多万种商品的在线价格,计算每日价格指数作为美国、阿根廷等20多个国家每日更新的通货膨胀指数,提供给各国央行和金融机构,并认为以这种方法构建的通货膨胀指数避免了政府在收集、计算和发布时的种种弊端,更接近真实水平,如阿根廷政府公布的2007—2011年的年平均通货膨胀率为8%,但通过在线价格数据计算的CPI超过了20%,远超政府官方数据,但和很多当地经济学家的判断、家庭调查数据的结果吻合。李凤岐等(2017)[7] 提出了自动挖掘百度搜索查询指数与经济指标之间关系的搜索预测算法,筛选出具有代表性的查询数据预测经济指标,并以此作为先行指标对我国CPI等宏观经济指标进行了预测。Askitas和Zimmermann(2013)[8] 从交通流量反映经济活跃程度的角度出发,用德国收费站记录的月度重型卡车越境数据建立了收费站指数,作为生产指数这一GNP指数先导指标的先行指标,用以现时预测商业周期,并实证了该指数能有效先行反映德国统计办公室官方发布的生产指数。Sutton等(2002)[9] ,Elvidge等(2007)[10] ,Henderson等(2012)[11] ,Mellander等(2013)[12] ,徐康宁等(2015)[13] ,范子英等(2016)[14] ,丁焕峰等(2017)[15] 从NASA卫星拍摄的夜间灯光强度数据出发,寻找其与经济活动之间的关系,认为灯光强度可反映经济运行情况,特别是认为灯光亮度与GDP存在非常显著的正向关系,可在一定条件下作为GDP的替代量。Askitas和Zimmermann(2009)[1] 通过检验德国月度失业数据和失业相关搜索数据的频率后,认为它们之间具有很强的相关性,网络搜索数据对预测失业率很有帮助。Edelman(2012)[16] 利用Monster.com上职位的供应量和求职者的申请数量的变化预测失业率。Amuri和Marcucci(2010)[17] ,McLaren和Shanbhogue(2011)[18] ,Vicente等(2015)[19] 均采用搜索数据预测了不同国家的失业率,实证验证均取得了较好效果。Kholodilin等(2009)认为由于google搜索数据指标由于数据更新快、覆盖群体广等原因,在预测经济衰退时期美国个人消费指数效果要优于传统指标。沈淑等(2015)[20] 根据消费者的行为理论,提出了一种基于LASSO机器学习理论和KPLSR方法的网络大数据对消费信心指数的预测方法。
在构建新的经济预测指标方面,由于大数据比传统数据来源范围广泛、更新及时、内容海量,经济学家得以构建许多具有经济意义的新指标,丰富并强化了对经济的预测能力。Chamberlain(2010)[21] 研究发现网络搜索数据和产品零售量间具有正相关性,可通过搜索数据构建产品销售的预测指标。Mclaren(2011)等[18] 认为可从网络搜索数据中建立现时经济活动指标,他们用Google Insights for Search数据建立了比政府官方发布更及时的英国住房市场和劳动力市场现时经济指标,并通过样本外检验验证了该系列指标的有效性。Dzielinski(2011)[22] ,Aastveit等(2013)[23] ,Iskyan(2016)分别基于Google搜索数据、含有“不确定性”相关词的文章数量测量并预测了宏观经济的不确定性指数。Wu和Brynjolfsson(2009)[24] 使用Google搜索数据预测了房地产价格指数。姜文杰等(2016)以均衡价格理论为基础,使用搜索关键词频率百度指数,采用自回归移动平均模型和带搜索项的自回归分布滞后模型研究并预测了上海房价。Choi和Varian(2010)[25] 强调Google趋势数据可用于预测当下,而不是预测未来,他们认为从表征用户行为特征的网络搜索数据中可以更早地发现经济变化,通过建立包含相应Google趋势变量的季节性AR模型预测了临近期的经济指标:美国汽车销量、旅行目的地行情、消费信心等,并验证了该方法比传统方法的准确度提高了5—20%。类似地,Artola等(2015)[26] 分别使用传统的由TRAMO估计的最好ARIMA模型、增加了相关Google搜索指数的模型短期预测了由德国、英国和法国去西班牙旅游的人数,发现后者在2012以前的预测精度比前者高42%。许伟(2016)[27] 通过结合Google搜索数据和网络新闻情感,构建了基于网络情感和搜索行为的数据挖掘集成模型,在其中加入房地产价格指数时间序列的滞后项,利用支持向量回归SVR模型,实现了对房地产价格指数的预测。Kim等(2015)用社会网络数据和机器学习算法建立了电影票房预测模型,并验证了该模型能有效提高预测水平。
在建立经济变量间的联系方面,大数据覆盖广,各种关系隐藏在表面看似无关的变量数据中,如何通过相关性分析挖掘、建立经济变量间的联系是基于大数据方法经济研究最令人兴奋的主题,它往往能深刻地揭示事物间的内在联系和发展规律,在这一领域的发现往往令人激动,改变人们的传统观点,甚至改变已有理论,某种程度上这也是大数据在经济研究方面本质、核心的意义。Antweiler等(2004),Mittermayer(2004),Das等(2007),Sehgal等(2007),Chen等(2009),Fand等(2009),Gilbert等(2010),Sheng等(2011),Xu等(2012)等均研究了财经网站信息、论坛等社交媒体内容反映的投资者情绪等对金融股市的影响。Liu等(2007)[28] 用PLSA算法(Probability Latent Semantic Analysis)从博客内容数据中挖掘用户观点和情绪用以预测销售,并用电影数据验证了考虑情感信息的方法预测精度较好。Bollen等(2011)[2] 研究了基于Twitter内容的公众情绪是否会影响股市,他们用两种情绪跟踪工具——测量正情绪和负情绪的Opinion Finder从6个维度量化测量情绪的情绪状态Google画像对每日Twitter内容的公共情绪进行测量,建立公共情绪和股市间的模糊神经网络模型,认为考虑公共情绪的方法能有效提高股市预测。Joseph(2011)研究了在线股票搜索与股票收益等的关系,认为某只股票的在线搜索数据是该只股票的收益及交易量的可靠的预测指标。Bordino(2012)的研究也发现网络用户对纳斯达克上市的股票的日常搜索查询语句的数量与该股票的交易量具有相关性。Moat等(2014)[29] 研究了Google和Wikipedia上有关金融的搜索数据和股市运行间的关系,认为从在线搜索数据建立的先行指标能有效预测股市的涨跌。Li等(2016)[30] 为研究微观层面上中小企业业绩受和政府、行业、学术界联系的影响,用网络爬虫工具挖掘271家中小型美国绿色食品和制造公司网站的信息数据,从中建立政府、行业、学界的联系对销售增长的面板回归模型,验证了企业和政府、行业、学界的联系对销售有正向影响。Arora等(2016)用网络爬虫工具Wayback Machine从300家美国中小型绿色食品企业网站的归档数据中挖掘企业创新和战略指标。Domenech等(2012)认为企业的经济活动和企业网站的信息有较强联系,通过分析企业网站信息便可以推断出很多企业的经济指标,他们建立了从企业网站数据实时得出网站经济指标到企业经济指标的模型,并用总部在西班牙瓦伦西亚的10000家企业作为样本进行了实证研究。Khadivi等(2016)通过分析Wikipedia使用数据(Wikipedia Usage Trends,WUTs),构建旅游需求和WUTs间的线性自回归模型,预测了夏威夷的旅游需求,认为该方法提高了预测精度。Chong等(2015)[31] 为比较在线促销和在线评论对预测消费者购买产品的影响,基于Amazon.com的数据,建立了产品销量和折扣、免运费、用户好评、差评等变量间的神经网络预测模型,发现上述变量均能影响销售,但用户评论的影响更大。Schneider等(2016)[32] 用词袋模型(Bag-of-Words)自动处理用户评论文本、用随机预测技术降维回归元,基于Amazon.com的用户评论预测了一周后的笔记本电脑的销售情况,认为预测结果要优于没有考虑用户评论的模型。Arenas-Marquez等(2014)对Ciao.com的评论影响研究了评论者在社会网络中的地位、评论的数量、转发数量等因素对转发数量等因素对其评论影响的影响。Li等(2015)从TripAdvisor.com的118,000条用户评论数据中探寻用户的潜在旅游偏好以帮助酒店改善服务。Hu等(2012)[33] 用统计方法研究了虚假评论对消费者购买的影响,认为约10%的产品购买受到了商家的虚假评论而影响。Wang等(2016),Suhara等(2017)通过对APP数据日志的情景分析和协同过滤算法预测了用户使用某些关联APP的意愿。Xiong等(2013)利用信用卡交易序列数据,使用支持向量机分类算法研究了对个人信用破产的预测。Vlasselaer等(2015)利用RFM(Recency-Frequency-Mone-tary)模型、客户消费历史、客户和商家的网络关系等提出了一种自动检测在线虚假交易的方法。Dey等(2014)用零售商电子扫描设备记录的数据分析了美国的鲢鱼市场的价格、销量的趋势,根据结果强调了市场上增加附加值等非价格竞争策略的重要性。Kitchin(2014)研究了智慧城市的WIFI、公共交通读卡器等数据在经济社会预测方面的应用。Chou等(2016)研究了基于智能电网大数据进而帮助预测、优化建筑节能、提高能源使用效率的方法。Williams等(2015)等提出了基于手机通信记录数据和GIS地理信息系统数据测量、预测人口流动性的方法。Montoliu等(2013)通过智能手机的位置数据,使用两层聚类算法研究了人们生活中经常所处的位置。Chittaranjan等(2013)使用机器学习算法研究了智能手机数据与五大人格维度的关系,认为可以从智能手机使用数据中挖掘出用户个性,用以改善企业的经营和销售。
二、主要研究方法介绍
由于绝大部分大数据原始状态为非结构化数据(Gandomi和Haider(2015)[34] 认为95%以上的大数据都是非结构化的),如何处理海量的非结构化数据、从中获取有效信息是经济学家面临的关键问题。与传统经济研究的方法相比,基于大数据方法的特征主要体现在数据抓取和数据分析方面:
(一)数据抓取(数据挖掘)
不同于传统上经济学家被动依靠政府、机构发布的结构化数据、或者主动对结构化数据操作,基于大数据研究经济首先要解决的是如何主动从不同渠道、海量、不断变动的非结构化数据中提取可直接用于分析的有用数据。目前对数据挖掘认同率较高的表述为从大量非结构化数据集中找到隐藏的信息:将大量数据作为输入,隐藏信息作为过程的输出,整个挖掘过程就是从输入到输出的一个映射。许伟(2016)[28] 认为根据数据挖掘的对象不同可分为网络结构挖掘、内容挖掘和应用挖掘:结构挖掘是通过分析网页之间的某个链接及与这个链接相关的网页数和相关对象,进而建立起网络链接结构模型;内容挖掘是通过分类和聚类技术,从页面内容本身提取到有价值的信息;应用挖掘从用户的行为信息中推断用户的特征。
由于来自互联网的大数据主要是记录人们行为的文本,自然语言处理算法(Natural Language Processing)得到大量应用,它是指让计算机像人类一样能读懂人类的文本,从非结构化的文本数据中提取有效信息。目前使用较广泛的NLP算法有:情感分析(Sentiment Analysis, SA)、主题模型(Latent Semantic Analysis, LSA)、潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)、词嵌入(Word Embeddings, WE)、数据匹配算法(Data Matching, DM)等。
数据挖掘的一般过程是(刘涛雄(2015)[35] ):借鉴抽样估计、人工智能、机器学习的搜索算法、建模技术和学习理论,利用网络爬虫软件通过云计算等分布式并行计算方法从网络抓取原始数据,然后通过探索性数据分析(Exploratory Data Analysis, EDA)和一致性检验清洗数据,过滤大量无用的噪声数据,保留值得加工的信息,最后对剩下内容进行加工提取,转化为一定程度结构化的可用数据,如标准化的时间序列等。数据清理并无规章可寻,实践中的主流数据清理工具有OpenRefine和DataWrangler。Varian(2014)[36] 总结了目前主流的用于数据挖掘的开源工具,如表1所示。
表1 数据挖掘工具
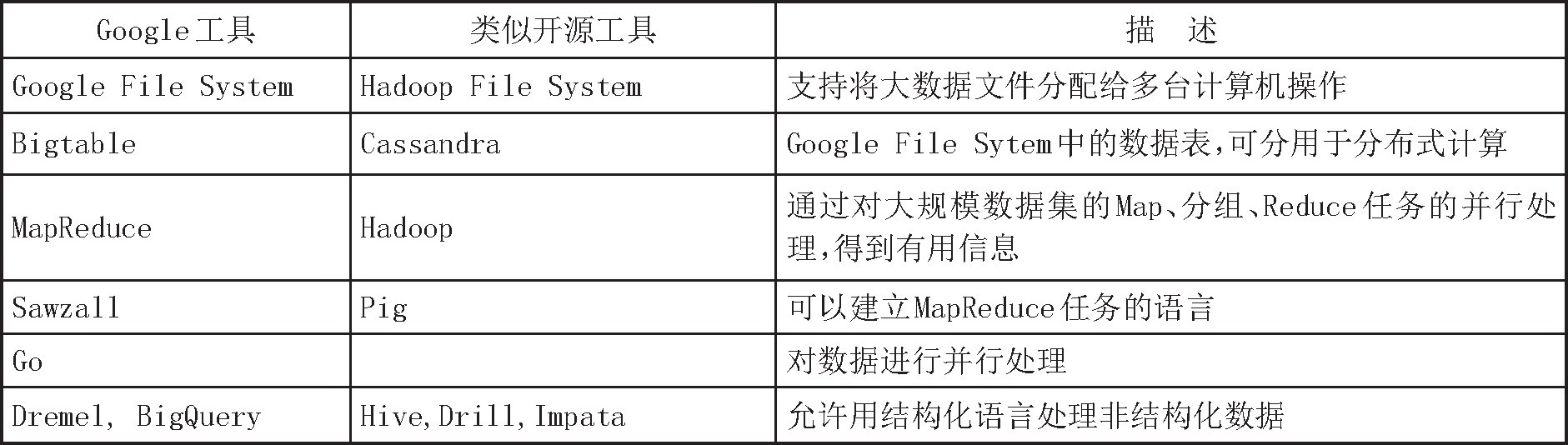
资料来源:Varian(2014)。
(二)数据分析
从数据中建模是大数据分析的关键,包括数据集降维、寻找数据间的关系。传统上经济学家大量应用线性和逻辑回归等算法建立数据间的联系,Varian(2014)认为针对大数据分析发展起来的一系列机器学习算法能更有效地处理海量数据问题。目前的大数据建模方法主要有两类:有监督学习(Supervised Learning)、无监督学习(Unsupervised Learning),有监督学习通过建立回归、分类模型,寻找输入数据和输出数据间的关系,根据输入推断输出;无监督学习通过聚类模型等寻找输入数据之间的关系或结构,构建描述数据行为的规则。目前有监督学习算法在经济研究中现时预测和邻近预测中应用更广,包括:决策树(Decision Trees,DT)、支持向量机(Support Vector Machine, SVM)、人工神经网络(Artificial Neural Networks, ANN)、深度学习(Deep Learning, DL)等算法。为解决样本数据过度拟合、维数过高、模型对样本外数据却表现欠优的问题,经济学家提出了添加随机量的集成算法(Ensemble Algorithms, EA)以解决过度拟合和降维问题,这些方法包括自举法(Bootsratp)、装袋方法(Bagging)、提升算法(Boosting)、随机森林(Random Forests)、属于正则化方法的套索算法(Least Absolute Shrinkage and Selection Operator, LASSO)、弹性网络(Elastic Net, EN)、岭回归(Ridge Regression, RR)、贝叶斯方法(Bayesian Methods, BM)、贝叶斯模型平均算法(Bayesian Model Averaging, BMA)、朴素贝叶斯(Naive Bayes, NB)、钉板回归(Spike-and-Slab Regression, SSR)等算法作为对线性回归的补充,在处理面板数据、纵向数据、时间序列数据上,经济学家提出了贝叶斯结构时间序列算法(Bayesian Structure Time Series, BSTS)作为对传统自回归(AR)和平均回归(MR)模型的补充。
为检验数据建模的准确性,经济学家一般把数据分为训练集和测试集,用训练集建立模型,用测试集检验模型,当数据容量足够大时可分为三部分:训练集、验证集和测试集。鉴于大数据复杂特性,经济学家在机器学习中采用K折交叉检验(K-Fold Cross-Validation),数据被划分为K个子集,模型拟合K次,每一次都用K-1个训练集、剩下1个用于预测测试,当每个子集仅有一个观测量时便退化为一次性交叉检验(Leave-one-out Cross Validation)(Blazquez等(2017)[37] )。从文献上看,目前阶段经典计量经济学的拟合优度判定系数R2、Hosmer-Lemeshow(HL)拟合优度检验、马洛斯Cp检验(Mallows'Cp)、赤池信息量准则(Akaike Information Criterion, AIC)、贝叶斯信息量准则(Bayesian Informa- tion Criterion, BIC)、偏差和对数似然检验等检验方法仍用于对基于大数据建立模型的检验。
三、主要研究和应用方向
从众多文献中,通过归纳可见基于大数据研究经济的直接目的可以大致分为:优化传统经济指标或构建其先行指标、构建新的经济预测指标、建立经济变量间的联系,其意在借助传统上不易或无法处理的、或曾经被忽视的海量非结构化数据,在数据间通过相关性分析发现数据间的联系,进而揭示更加深刻意义上的经济联系。因此,虽然本质上一样,但目前基于大数据方法研究经济主要分两个方向:经济预测和验证经济理论。
从研究文献的内容来看,目前大多数经济学家们倾向于主动选择、构造数据集,从中进行数据分析以解释或发现经济现象,并在模型得到验证后在数据更新较快时进行现时预测。无论是前文提到的“十亿价格计划”、“收费站指数”,还是“房价预测模型”,都遵循同样的基本思路。通过对传统意义上难以甚至无法获得的数据,构建经济模型是这个方向研究的重点和关键,和实时更新的数据一起构成了基于大数据方法预测经济的独特优势。基于大数据方法的经济预测大幅缩短了预测周期,现时预测是传统方法难以有效实现的,这对政府、机构、企业及时准确掌握经济运行情况、制定经济政策和做出企业决策具有重要意义,政府可以根据国民经济运行情况及预测及时出台相关刺激或抑制政策,企业可以根据经济预测提前布局生产经营。由于大数据时代计算、网络技术的进步,各类数据、行为、现象均被记录,数据的触角极大增加,如何从中挖掘出具有经济意义的模型,特别是从传统方法上难以获得数据、经济人行为上获取有用信息,一般的原则是从经济学的基本原理出发,通过增加或者调整经济变量体现大数据的存在,如传统上对房价的研究主要体现在土地供给、新增投资、房屋供求量、货币政策等因素上,基于大数据的方法则从传统方法很难获取的用户行为出发,考虑房价和相关搜索之间的关系,增加了用户的相关搜索量作为一个经济变量,进而预测房价。研究股市波动时也把有关股市的搜索、媒体的情感等传统上难以量化的指标作为明确的经济变量加以分析。因此,基于大数据研究经济的方法在很多方面不是对传统经济学研究方法的颠覆,它更是一个对传统研究方法的补充。
在验证经济理论方面,由于大数据包罗万象,可以微观到每个用户的行为、使用留下的痕迹、每次电子商务购买的交易、每次网站的点击等传统意义上无法观测或统计的数据,从而可以使经济学的研究更加深入,海量的数据也为验证、发现经济理论提供了实证基石。例如,通过分析就业网站提供的职位信息、用户对求职相关的搜索等数据可以从微观上分析失业者在寻求就业时的影响因素,对相关社交媒体信息和商品销售的分析可以从行为经济学上研究消费者购买的影响因素。历史上的重大发明、创新很多都是从数据出发,如菲利普斯从失业和经济增长的数据中发现菲利普斯曲线,库兹涅夫从收入和分配数据中发现库兹涅夫曲线,而大数据包含了很多传统意义上无法获取或统计的行为、心理数据,以及由之构成的可清洗解剖的宏观数据,大数据时代的全方位、海量数据也是经济学家发现新的经济理论、规则的无穷宝藏,对经济学的发展有重要意义。
四、当前面临的主要问题
由于大数据拥有的众多特点,其在经济学上的应用得到了较快发展,但仍面临一些问题。主要体现在:
第一,经济学家对大数据的获取难。由于大数据主要由政府、互联网公司、银行等机构掌握,而在数据日益被视为重要财富、私有资源的数据时代,经济学家要获得需要的大数据资源面临着数据所有者和法律、道德的多重限制,这会影响经济学家基于大数据做研究,也是目前大量的经济研究仅依赖搜索数据这单一渠道的原因之一。要促进大数据在经济研究中的应用,解决好大数据的来源问题是至关重要的一环。
第二,经济学家对大数据的获取和处理的能力面临困境。“大数据”本身是一个从计算机领域产生的术语,经济学家真正把眼光投向大数据也是最近十几年的事情,基于大数据的研究融合了计算机、网络、信息、数学、经济学、心理学等学科的前沿知识,是一项非常复杂的研究工作,经济学家对传统的基于统计学的经济研究很擅长,但对数据挖掘、机器学习等数据处理方法普遍比较陌生,目前很多基于大数据的研究是在计算机专家的协助下开展的,这在一定程度上限制了大数据在经济学研究上的应用,经济学家从思维上转变对大数据方法是“术”的观点、掌握大数据的获取和分析技术很紧迫。唯有如此,方能真正凸显大数据的力量。
第三,基于大数据的经济分析方法的某些理论基础没有夯实。如由于大数据的数据海量,建立的经济模型存在维数很高的问题,且变量之间可能存在相关性,目前通行办法是降维,但大数据方法又不同于传统计量经济,降维的理论意义仍存在争议。对基于大数据的方法本质上是属于基于总体的方法,还是和传统样本分析方法一样等问题也存在争议。数据爆炸时代经济学家对同一经济问题会有很多种数据支撑,如何辨别、是否存在正确的数据解释也带来了一些经济概念意义上的混乱。目前基于大数据的分析主要是寻找变量间的相关性,而不是因果关系,基于大数据的经济解释能力有待进步。
五、总结和展望
“大数据”、“人工智能”等发端于计算机、互联网领域的名词注解了这个时代,数据呈爆炸性、指数式增长,人类同时也拥有空前的对数据获取和处理的能力,“经济学帝国”自觉地把大数据纳入了麾下。基于大数据研究经济在数据的来源、渠道方面,数据处理和分析方面,方法论等方面均与传统经济学研究方法有很大区别。大数据方法研究的核心是相关性分析。虽然大数据来源、内容、处理方法不一样,但根据经济研究中使用大数据研究的目的,国内外大量的基于大数据研究经济的文献可以大致归纳为3类:优化传统经济指标或构建其先行指标、构建新的经济预测指标、建立经济变量间的联系。由于绝大部分大数据原始状态为非结构化数据,如何处理海量的非结构化数据、从中获取有效信息是经济学家面临的关键问题。与传统经济研究的方法相比,基于大数据方法的特征主要体现在数据抓取和数据分析方面。基于大数据的经济分析意在借助传统上不易或无法处理的、或曾经被忽视的海量非结构化数据,在数据间通过相关性分析发现数据间的联系,进而揭示更加深刻意义上的经济联系,虽然本质上一样,但目前基于大数据方法研究经济主要分两个方向:经济预测和验证经济理论,对国民经济运行、企业决策、经济学发展均有重要意义。
当前基于大数据研究经济面临的主要问题在于大数据获取难、数据处理和分析难、基于大数据的经济分析方法的某些理论基础没有夯实。虽然仍然存在不少问题,但随着信息化、智能化技术的不断发展,数据的重要性会不断增加,人们对大数据会愈发依赖,如果数据对于经济学是重要的,则基于大数据方法的研究是经济学发展的方向之一。对我国而言,一是要探索建立经济学家使用大数据资源的机制和渠道,在保证数据安全、公众隐私、机构利益的前提下,使政府、公共机构、公司收集的数据能得到有效利用,进而造福社会;二是要提高经济学家处理、分析大数据的能力,适应大数据时代的信息处理和分析环境,培养复合型的经济学家;三是要继续加强对大数据经济研究基础理论工作的研究,针对大数据的特性建立相关的统计分析理论,夯实经济学利用大数据的理论基石。
参考文献
[1] ASKITAS N,ZIMMERMANN K F,Google Econometrics and Unemployment Forecasting[C] .Discussion Paper of Diw Berlin,2009(, 55):107-120.
[2] BOLLEN J,MAO H, ZENG X,Twitter Mood Predicts the Stock Market[J] . Journal of Computational Science, 2011, 2(1):1-8.
[3] CAVALLO A, Online and Official Price Indexes: Measuring Argentina's Inflation[J] .Journal of Monetary Economics,2013,60(2):152-165.
[4] BRANDYN BOK,DANIELE CARATELLI,DOMENICO GIANNONE, ARGIA SBORDONE, ANDREA TAMBALOT. Macroeconomic Nowcasting and Forecasting with Big Data[R] . Federal Reserve Bank of New York Staff Reports, no. 830,2017.
[5] V M SCHONBERGER.Big Data: A Revolution That Will Transform How We Live, Work and Think[M] .London, UK: John Murray Publishers Ltd, 2013.
[6] A CAVALLO, R RIGOBON.The Billion Price Project: Using Online Prices for Measurement and Research[J] .Journal of Economic Perspective, 2016, 30(2):151-178.
[7] 李凤岐,李光明.基于搜索行为的经济指标预测方法[J] .计算机工程与应用,2017(, 6):215-222.
[8] ASKITAS N,ZIMMERMANN K F.Nowcasting Business Bycles Bsing Boll Data[J] .Forecast, 2013,32(4):299-306.
[9] P SUTTON,D ROBERTS,C ELVIDGE,K BAUGH.Census from Heaven: An Estimate of the Global Human Population Using Night-time Satellite Imagery[J] .International Journal of Remote Sensing, 2001,22(16):3061-3076.
[10] PC SUTTON,CD ELVIDGE,T GHOSH. Estimation of Gross Domestic Product at Sub-national Scales Using Night-time Satellite Imagery[J] .International Journal of Ecological Economics& Statistics,2007,8(Suppl 7):5-21.
[11] HENDERSON J V,STOREYGARD A,WEIL D N. Measuring Economic Growth from Outer Space[R/OL] .NBER research paper, http://www.nber.org/papers/w15199.
[12] MELLANDER S,STOLARICK K, MATHESON Z, LOBO J. Night-time light Data: A Good Proxy Measure for Economic Activity? [J] .Plos one, 2015,10(10).
[13] 徐康宁,陈丰龙,刘修岩. 中国经济增长的真实性:基于全球夜间灯光数据的检验[J] . 经济研究,2015(, 9):17-29.
[14] 范子英,彭 飞,刘 冲. 政治关联与经济增长——基于卫星灯光数据的研究[J] . 经济研究,2016(, 1):114-126.
[15] 丁焕峰,周艳霞.从夜间灯光看中国区域经济发展时空格局[J] .宏观经济研究,2017(, 3):128-136. [16] EDELMAN B. Using Internet Data for Economic Research[J] .Journal of Economic Perspectives, 2012,26(2):189-206.
[17] AMURI D F, MARCUCCI J. Forecasting the US Unemployment Rate with a Google Job Search Index[R] .Social Science Electronic Publishing, 2010.
[18] MCLAREN N, SHANBHOGUE R. Using Internet Search Data as Economic Indicators[J] .Bank Engl. Q. Bull. 2011,Q2, 134-140.
[19] ICENTE M R,LOPEZ MENENDEZ A J, PEREZ R. Forecasting Unemployment with Internet Search Data: Does It Help to Improve Prediction When Job Destruction is Skyrocketing?[J] .Technological Forecasting & Social Change, 2015,92(92): 132-139.
[20] 沈 淑,张 璇,田晓春.网络大数据在消费者信息指数预测中的应用——基于 LASSO 算法和 KPLSR 算法[C] .2015 年第四届全国大学生统计建模大赛,2015.
[21] CHAMBERLAIN G. Googling the Present [J] .Economic and Labour Markert Review, 2010,4(12).
[22] DZIELINSKI M, News Senstivity and the Cross-section of Stock Returns[R] .NCCR Finrisk working paper no.719, 2011.
[23] AASTVEIT, KNUT ARE, GISLE JAMES NATVIK, SERGIO SOLA, Economic Uncertainty and the Effectiveness of Monetary Policy[R]. Norges Bank, 2013.
[24] WU L, BRYNJOLFSSON E. The Future of Prediction: How Google Searched Foreshadow Housing Prices and Sales[C] .Social Science Electronic Publishing, 2014:89-118.
[25] CHOI H, VARIAN H. Predicting Initial Claims for Unemployment Benefits[J] .Social Science Electronic Publishing, 2010.
[26] ARTOLAS N, PINTO F, Can Internet Searches Forecast Tourism Inflows? [J] .International Journal of Manpower, 2015,36(1).
[27] 许 伟. 基于网络大数据的社会经济监测预警研究[M] . 北京:科学出版社,2016.
[28] LIU Y, HUANG X, AN A, YU X. Sentiment Aware Model for Predicting Sales Performance Using Blogs[C] .The 30th Annual International Acm Sigir Conference on Research and Development in Information Retrieval, 2007:607-614.
[29] MOAT H S, CURME C, STANLEY H E, PREIS T. Anticipating Stock Market Movement with Google and Wikipedia[C] .NATO Science for Peace and Security Series C: Environmental Security Springer Science, 2013:47-59.
[30] LI Y, ARORA S, YOUTIE J, SHAPIRA P. Using Web Mining to Explore Triple Helix Influences on Growth in Small and Mid-size Firms[J/OL] . Technovation, 2016, http://dx.doi.org/10.1016/j.technovation.2016.01.002
[31] CHONG A Y L, LIU M, LI B. Predicting Consumer Product Demands Via Big Data: The Role of Online Promotional Marketing and Online Reviews[J] .International Journal of Production Research, 2015:1-15.
[32] SCHNEIDER M J, GUPTA S. Forecasting Sales of New and Existing Products Using Consumer Reviews: A Random Projections Approach[J] .International Journal of Forecasting, 2016,32(2):243-256.
[33] HU N, BOSE I, KOH N S, LIU I. Manipulation of Online Reviews: An Analysis of Rating, Readability, and Sentiments[J] .Decision support system, 2012,52(3):674-684.
[34] GANDOMI A, HAIDER M. Beyond the hype;Big Data Concepts, Methods, and Analytics[J] .International Journal of In⁃ formation Management, 2015,35(2):137-144.
[35] 刘涛雄,徐晓飞.大数据与宏观经济分析研究综述[J] .国外理论动态,2015,(1):57-64.
[36] VARIAN H R. Big Data: New Tricks for Econometrics [J] .Journal of Economic Perspective,2014,28(2):3-28.
[37] BLAZQUEZ D, DOMENECH J.Big Data Sources and Methods for Social and Economic Analyses[J/OL] .Technological Forecasting & Social Change, 2017, https://doi.org/10.1016/j.techfore.2017.07.027.